
Following the previous blog where we discussed some important features of bigquery – Clustering and Partitioning. And we left on a question that, are these the only way to improve query performance? And as you already know the answer is ‘No’.
So, What is that technique/feature? 🤔
Query performance can be optimized/improved by choosing the right/appropriate Table Schema.
What do I mean by choosing the right schema?
Let’s look into EPA PM10 hourly dataset, which is available at BigQuery Public Dataset. This dataset is originally a flatten dataset which means there’s a row for every hourly observation.
Now let’s query that table
Query-1
SELECT
pm10.county_name,
COUNT(DISTINCT pm10.site_num) AS num_instruments
FROM
`bigquery-public-data`.epa_historical_air_quality.pm10_hourly_summary as pm10
WHERE
EXTRACT(YEAR from pm10.date_local) = 2018 AND
pm10.state_name = 'Ohio'
GROUP BY pm10.county_name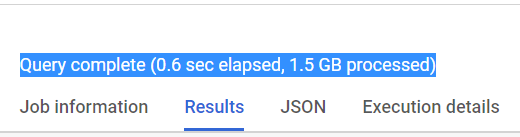
Query-2
SELECT
MIN(EXTRACT(YEAR from pm10.date_local)) AS year
, MAX(pm10.sample_measurement) AS PM10
FROM
`bigquery-public-data`.epa_historical_air_quality.pm10_hourly_summary as pm10
CROSS JOIN
`bigquery-public-data`.utility_us.us_cities_area as city
WHERE
pm10.state_name = 'Ohio' AND
city.name = 'Columbus, OH' AND
ST_Within( ST_GeogPoint(pm10.longitude, pm10.latitude),
city.city_geom )
GROUP BY EXTRACT(YEAR from pm10.date_local)
ORDER BY year ASC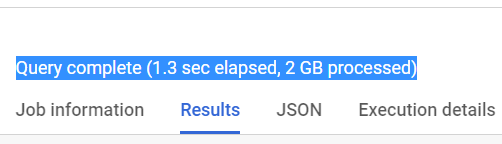
The EPA hourly data is in a table whose rows have an hourly observation. This means that there’s a lot of repeated data about stations, etc. So we can combine a single day’s observation in an array with ARRAY_AGG() i.e. we are reducing the number of rows losslessly (table size will be the same but number of rows will be less).
Let’s create new table with same data but less rows.
CREATE OR REPLACE TABLE advdata.epa AS
SELECT
state_code
, county_code
, site_num
, parameter_code
, poc
, MIN(latitude) as latitude
, MIN(longitude) as longitude
, MIN(datum) as datum
, MIN(parameter_name) as parameter_name
, date_local
, ARRAY_AGG(STRUCT(time_local, date_gmt, sample_measurement, uncertainty, qualifier, date_of_last_change) ORDER BY time_local ASC) AS observations
, STRUCT(MIN(units_of_measure) as units_of_measure
, MIN(mdl) as mdl
, MIN(method_type) as method_type
, MIN(method_code) as method_code
, MIN(method_name) as method_name) AS method
, MIN(state_name) as state_name
, MIN(county_name) as county_name
FROM `bigquery-public-data.epa_historical_air_quality.pm10_hourly_summary`
GROUP BY state_code, county_code, site_num, parameter_code, poc, date_localNow run Query-1 and Query-2 on newly generated table
Query-1
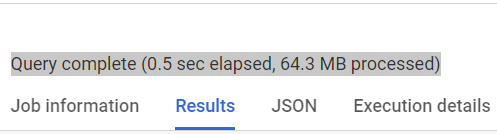
Query-2
For Query-2 we need to change our bigquery query as our schema is changed and we are fetching data from array of nested fields.
SELECT
MIN(EXTRACT(YEAR from pm10.date_local)) AS year
, MAX(pm10obs.sample_measurement) AS PM10
FROM
advdata.epa as pm10,
UNNEST(observations) as pm10obs
CROSS JOIN
`bigquery-public-data`.utility_us.us_cities_area as city
WHERE
city.name = 'Columbus, OH' AND
ST_Within( ST_GeogPoint(pm10.longitude, pm10.latitude),
city.city_geom )
GROUP BY EXTRACT(YEAR from pm10.date_local)
ORDER BY year ASC
It is clearly seen from the results that after altering the table schema, scanned data is pretty much less. i.e. storing data in nested and/or array fields has made our query almost 23x and 3x times less expensive respectively!!!😲
But why is it less expensive? 🤔
As already discussed, with the help of ARRAY_AGG() and nesting, no. of rows are reduced and data is organized more efficiently. So, BigQuery will have less rows to scan.
Here, even with scanning less data, the query runtime is not affected. It is due to the computations (max, extract year, ST_Within), which are the bulk of the overhead for this query and the number of rows those are carried out on is the same, so the query speed does not change.
So choose your table schema wisely!!!😀
Clustering, Partitioning and nesting and/or arrays allows BigQuery to organize data more efficiently which leads to higher performance and cheaper costing.
References:
- https://cloud.google.com/bigquery/docs/reference/standard-sql/aggregate_functions#array_agg
- https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types#struct_type