
BigQuery is a great tool to analyze huge amounts of data quickly but there are many times we only care about analyzing a subset of data, for example analyzing data over a particular period of time or over particular columns. But in the on-demand model you are charged on the basis of data volume which query scans i.e. “The more you scan, the more you pay”.
Is there any way to improve query performance in these scenarios??? 🤔
Can we reduce query cost??? 🤔
Guess what!!! The answer is Big Yes!!!! 🤩
To restrict the scanning of data BigQuery provides two prominent methods called Partition and Clustering, which can improve query performance and even reduce the query cost!!!
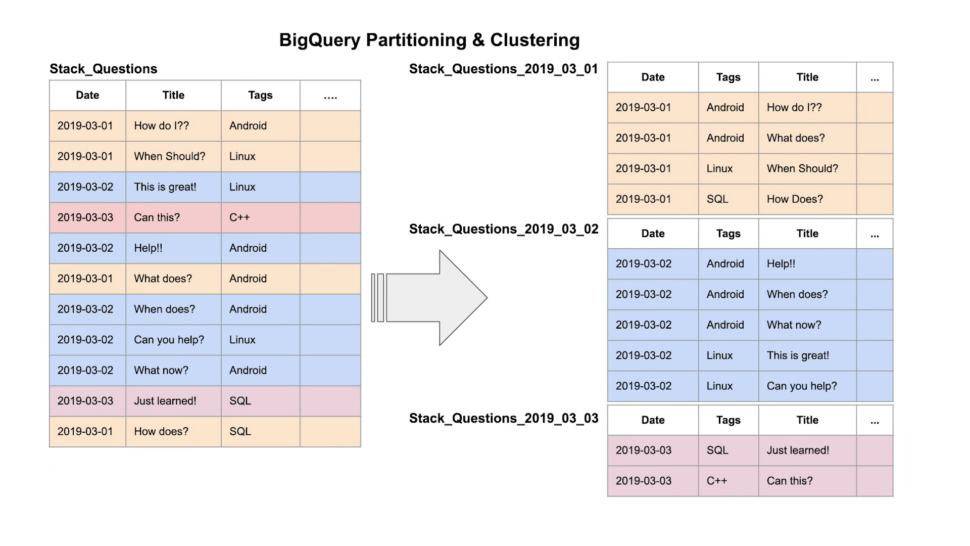
The table from the left side is the Standard table and the table from the right side is Partition on Date + Clustering on Tags.
The concept of a partitioned table is pretty much straight forward, it allows to split the data based on a timestamp/date column or over a numeric range. And clustering is nothing but sorting/grouping.
Let’s check the query performance on above mentioned tables for same query:
Select * from Table
Where Date between "2018-09-01" and "2019-03-01"
And Tags = "Android"
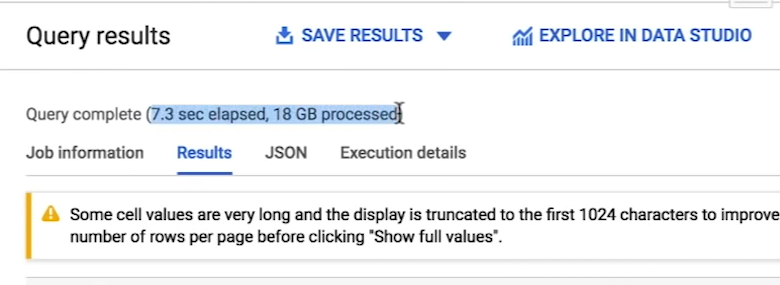
Limit 100For Standard Table:
For Partitioned and Clustered Table:
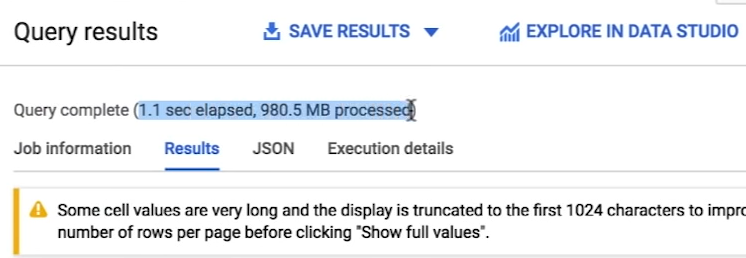
Over here it is clearly seen that the partitioned + clustered table took almost 7x times faster and scanned almost 18x times less data!!!😲 Which shows the power of partition and clustering.
Now let’s talk about how we can leverage this power!
Apply partition and clustering on those column/s which are frequently in use with WHERE condition.
Some Important points to Note:
- It is possible to apply only clustering or partition and combination of both.
- Partition and Clustering should be applied while creating the table.
- Partition can be applied on only Date/Timestamp (time unit column), Ingestion time or Numeric (integer range) columns. We can also create our own customized partition field. To achieve this we need to transform the partition field to Numeric type.
- Partition can be applied to only one field.
- According to the BigQuery quota 4000 partitions are allowed per table.
- Clustering can be applied to any column (integer/string/timestamp etc).
- Maximum 3 columns can be added in clustering.
- Column order makes a difference in clustering, so choose wisely.
- Clustering and Partition can be applied to the same column.
- Partition and clustering can only be applied to top level fields i.e. it cannot be applied to a REPEATED (array based) field or a leaf field from RECORD (STRUCT).
In order to leverage Clustering and Partitioning first we need to create Partitioned and Clustered Table So let’s look into this
- With DDL (Data Definition Language) statement
CREATE TABLE
TableName (
TimeInSeconds INT64,
CustomerId STRING,
DeviceId STRING NOT,
StartTime TIMESTAMP,
)
PARTITION BY
RANGE_BUCKET(TimeInSeconds,
GENERATE_ARRAY(0, 4000, 1))
CLUSTER BY
StartTime,
CustomerId,
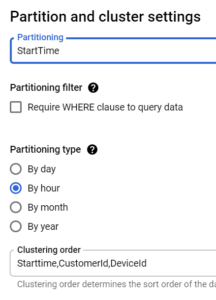
DeviceId;- From BigQuery UI
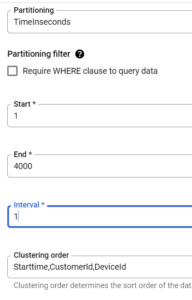
Always remember to partition and cluster your table. Why??? 🤔
Because, It is free, No special query changes are required, Make queries faster and cheaper!!!😀
Now the question arises, Is it the only way to improve query performance?🤔
And the Answer is “No”. You’ll find the description of the answer and subsequent approaches in my next blog. Stay tuned and happy learning!!!
References: