
If you are working or like to work on Python Data Science or Machine Learning you should know about Pandas, because this is one of the most useful and powerful libraries to analyze the different formats of data and make the work simple, accurate, and fast. In this blog I will explain some basics of a pandas data frame, I don’t want to make this complex, so here you can get what is useful to simplify your work. I hope you will like this
Pandas is a data analysis library in python that allows us to read, write and analyze the different types of data. It is one of the most popular libraries in python, it is very useful for Data Science and Machine Learning. Pandas is built on top of another python library named Numpy.
Panda is well optimized, so the analysis using pandas is very fast and it supports CSV, Excel and other similar formats.
Installation of pandas is very simple, run the below command on command prompt or terminal.
If you are using Mac then use the pip3 instead of pip
pip install pandasWhat can we do with Pandas DataFrame?
Pandas DataFrame is a table like data which contain rows and columns.
- Load data
- Save data
- Statistical Analysis
- Joins and Merges
- Group and Analyze
- Data Normalization and more
We can perform much more operations with pandas. In this blog, we are discussing how to read data from a file, how to write the analyzed data to the file, and some basic functionalities of pandas that we should know for better understanding.
How to load the data to the Pandas Dataframe
To load the data from a CSV file to a data frame we need to use the read_csv. Click here to download the sample CSV file which I have used in this blog.
import pandas as pd
df = pd.read_csv("Sample_Sales.csv")Now the data in the csv is loaded to the df. To read data from other formats also the same method.
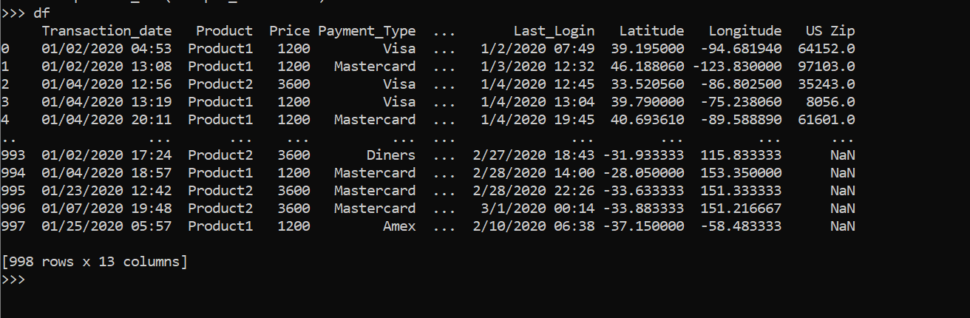
The above dataframe contains 998 rows and 13 columns. The 0,1….997 is the index
How to write data to the data frame and save
To create a data frame with our data, we need to create a dictionary with column names for keys, and for values, we need to add a list of data and use pd.DataFrame(dict_var), pd.DataFrame converts the dictionary into the data frame.
dict_var = {"Product":["product1", "product2", "product3"],
"Price": [1200, 1000, 1100],
"Payment_Type": ["Master Card", "Visa", "Cash"]}
df = pd.DataFrame(dict_var)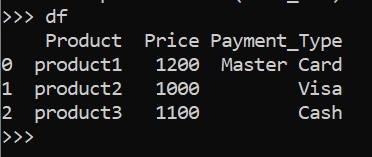
In the above example, Product, Price and Payment_Type are the keys of a dictionary they will become the column names and the values of the dictionaries are the row of the data frame.
We can also save the data frame to a file using the command df.to_format(“filename.extension”). Here format and extension are the file format and their extension to save the data in supporting formats. For example, if you want to save the above data frame to CSV format with a name sample.csv run the below command
df.to_csv("sample.csv")Basic functionalities in data frame
df.shape : It will return the number of rows and columns of a data frame
df.head() : Gives the first 5 rows. Similarly, we can extract any number of rows from the top using df.head(num_of_rows)
df.tail() : Gives the last 5 rows. Similarly, we can extract any number of rows from the bottom using df.tail(num_of_rows)
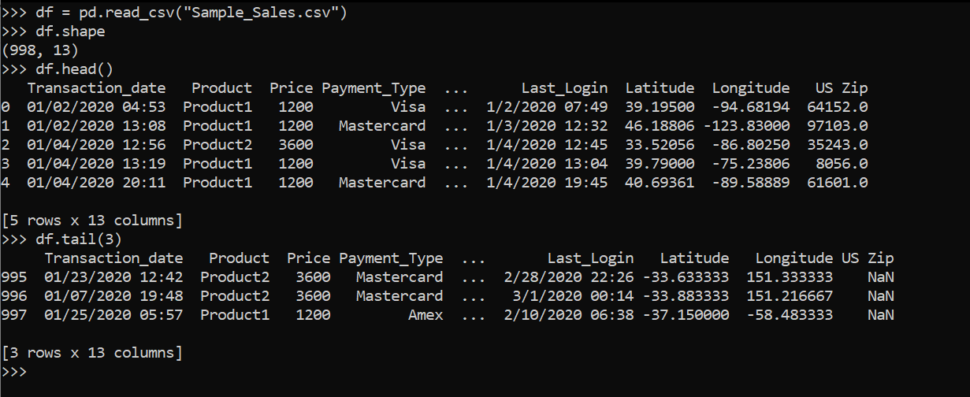
we can access the data in data frame just like dictionaries
There are two ways to access column data: using a dictionary key and another is dot format. Using the below commands we can access all the rows of the Payment_Type column.
df["Payment_Type"]
df.Payment_Type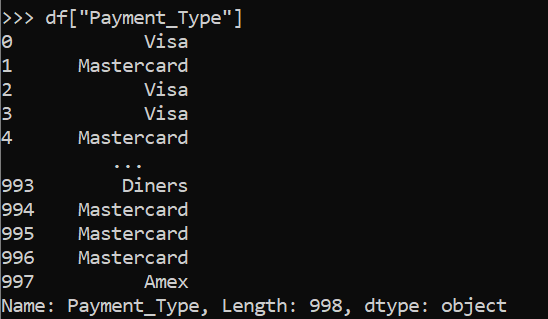
we can also access multiple columns by passing list of column names
df[["Product", "Payment_Type", "Price"]]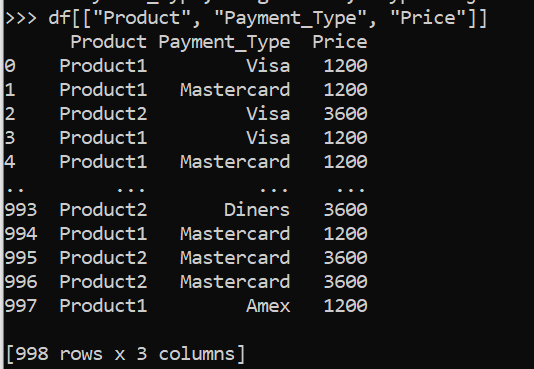
To access rows we can use loc or iloc. iloc is used to access row by their index values and loc is used to access rows by their label
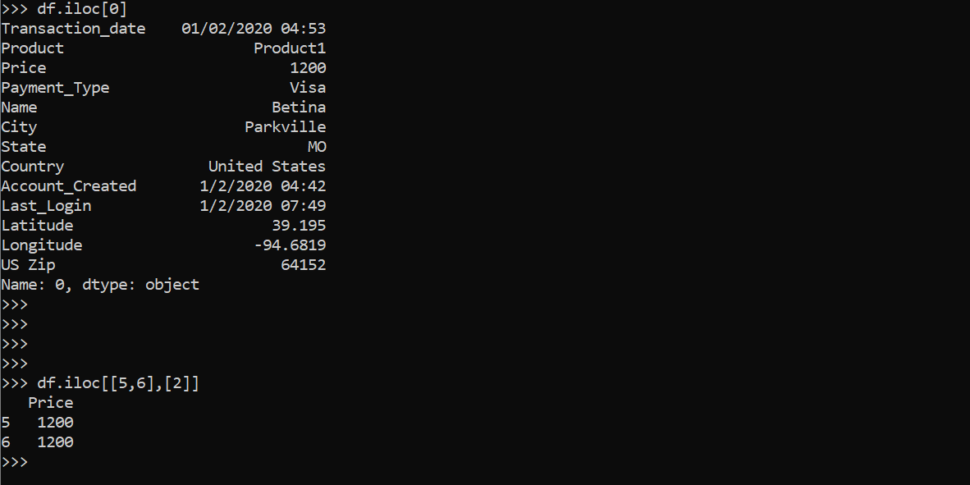
df.iloc[0] #It will return the first row of the dataframedf.iloc[[5,6],[2]]Here [5,6] is to access 5th and 6th rows and [2] to access 2nd column, so it will give us the 2nd column of the 5th and 6th row, here 2nd column is Price
We can also use slicing to get the range of rows and columns
df.loc[2:4,"Product":"Country"]
In the above example we are access the 2nd to 4th rows of Product to Country columns in the data frame
These are some basics of pandas, I have tried to make the topic simple and useful. I hope you enjoyed this article, If you find this article is helpful drop a comment below, and please share it with your friends and colleagues!